
Qu’est-ce qu’une base de données ?
Une base de données permet de stocker et de récupérer des données.
Ces données peuvent être extrêmement variées et l’organisation de celles-ci également.
Il peut s’agir de données très structurées (on parle alors de base de données relationnelles) ou au contraire très peu structurées (comme parfois dans le noSQL ).
Les systèmes de gestion de base de données
Les systèmes de gestion de base de données (SGBD ou DBMS en anglais) sont des ensembles de programme qui permettent de principalement gérer l’organisation et l’accès aux données.
Ils permettent d’ajouter, de lire, de mettre à jour et de supprimer les données, c’est-à-dire de réaliser les opérations CRUD (Create, Read, Update, Delete ).
Les autres tâches gérés par ces systèmes sont principalement :
Le contrôle d’accès : authentification et autorisation des opérations de lecture, d’écriture et d’administration de la base de données.
Vérification de la cohérence : vérification des opérations (contrôle d’unicité, règles d’intégrité référentielle etc).
Assurer la durabilité : réplication (les mêmes données sont écrites sur plusieurs disques / serveurs) et les sauvegardes ponctuelles.
Journalisation des opérations : chaque opération est enregistrée dans un fichier de log appelé journal qui permet d’annuler ou de terminer l’opération en cas d’erreur ou de crash.
Indexation : les index sont maintenus à jour à chaque opération.
Il existe aujourd’hui environ 300 systèmes de gestion de base de données actifs. Cela fait donc un large choix !
Le SQL et le noSQL
Le SQL (Structured Query Language ) est un langage permettant de gérer les bases de données relationnelles.
Ce type de base de données est apparu dans les années 1980 et 1990 avec principalement Oracle (1980), IBM Db2 (1983), Microsoft SQL Server (1989), PostgreSQL (1989) et MySQL (1995).
Il est standardisé depuis 1986 est le dernier standard est SQL:2019.
Le NoSQL (signifiant non-SQL, ou non relationnel ou encore not only SQL suivent les sources) est un terme désignant les bases de données qui ne sont pas relationnelles, c’est-à-dire qu’elles n’utilisent pas uniquement des tables relationnelles.
Elles sont apparues dans les années 2000 avec l’explosion du volume de données à traiter (pensez Facebook, Google, Youtube, Amazon etc). Nous sommes alors passés de base de données de quelques téraoctets à des bases de données faisant plusieurs pétaoctets (milliers de téraoctets).
La première génération de systèmes était totalement propriétaire avant que certains ne soient mis en open source après leur abandon ou mis à disposition dans une offre cloud commerciale. Des exemples de projets sont Big Table pour Google, DynamoDB pour Amazon, Voldemort pour Linkedin, Cassandra, puis HBase puis TAO pour Facebook, Hypertable pour Baidu etc.
Aujourd’hui on distingue trois grandes familles de système de base de données NoSQL :
Les open sources : le code est libre et l’utilisation gratuite. Par exemple, MongoDB, RocksDB, Redis, Elasticsearch etc. Les entreprises se rémunèrent en proposant une offre DBaaS (bases de données entièrement gérées dans le cloud ) ou une offre entreprise avec du support professionnel.
Les totalement propriétaires : ces systèmes sont souvent brevetés ou complètement secrets. Par exemple, TAO de Facebook, le système X d’Amazon (projet secret, même le nom est confidentiel).
Les propriétaires avec offre commerciale cloud : ce sont des systèmes développés par les acteurs du Cloud souhaitant vendre des DBaaS sur leurs infrastructures. Des exemples sont Google Spanner et Google BigTable, trop pour les nommer sur AWS (Neptune, DynamoDB et plusieurs dizaines d’autres) et pour Azure chez Microsoft nous avons par exemple Azure Cosmos DB.
Les modèle de stockage de données
Pour les bases de données SQL le stockage se fait avec des tables comportant des colonnes et des rangées. Il faut donc avoir une idée précise des relations entre ses données.
Pour les bases de données NoSQL le stockage dépend des bases de données, mais on peut distinguer des familles :
Orientées document : sur le modèle de documents JSON sans structure particulière. Chaque document contient des paires de champs / valeurs. Les valeurs peuvent être des chaînes de caractères, des nombres, des booléens, des tableaux et même des objets. Ce sont des bases de données general purpose adaptée à la majorité des cas d'utilisation. Par exemple : MongoDB ou Couchbase.
Orientées clé / valeur : permet de stocker des paires clé / valeur uniquement avec de grandes performances. Les données sont disponibles en RAM et persistées seulement à une intervalle configurable sur le disque. Leur performance est extrêmement élevée (une écriture ou un accès sur disque, même un SSD NVMe, est beaucoup moins rapide que la RAM). Elles sont utiles pour des données simples devant être très souvent lues ou écrites (comme par exemple du caching). Par exemple : Redis, RocksDB (Facebook),Voldemort (Linkedin) ou DynamoDB (Amazon).
Orientées colonnes : utilise des tables avec des rangées mais des colonnes dynamiques. Cela signifie que les rangées n’ont pas besoin d’avoir les mêmes colonnes. Le cas d’utilisation est un projet mature avec une très fine connaissance des requêtes effectuées et nécessitant un très grand nombre d’opérations d’écriture (jusqu’à quelques millions par seconde) sur des volumes énormes de données (plusieurs centaines de téraoctets ou pétaoctets). Pour de bonnes performances il faut le plus souvent une table par requête. Des exemples d’utilisation sont l’Internet des objets (IOT ) ou plus globalement des données horodatées (time-series data). Par exemple, Cassandra (Facebook), ScyllaDB ou Big Table (Google).
Orientées graphes : utilise des nœuds reliés par un ensemble d'arcs. Les nœuds sont par exemple des personnes ou des endroits et les arcs permettent de stocker les relations entre les nœuds. Ce type de base de données est utile lorsque le besoin principal est de traverser les relations (réseau social, détection des fraudes, moteur de recommandation). Par exemple, Neo4j, JanusGraph ou Amazon Neptune.
Orientées recherche ou index inversé : utilisées pour de la recherche textuelle très performante. Par exemple Elasticsearch ou Solr.
La montée en charge (scaling)
Historiquement, il était extrêmement complexe de faire monter en charge les bases de données SQL et seules certaines entreprises, développant leurs propres systèmes, y parvenaient (par exemple Facebook, voir plus bas).
Les entreprises n’ayant pas ces moyens devaient faire une montée en charge verticale (des serveurs de plus en plus puissants), ce qui est très coûteux et limité (un serveur ne peut pas avoir un CPU, RAM et espace disque illimité).
Les bases de données NoSQL sont généralement très simple à scaler car la division des données sur plusieurs instances (appelée sharding ) est prévue dans le système (on dit qu’elles sont distribuées by design). Il suffit donc d’ajouter des instances à votre base de données au fur et à mesure de l’augmentation des besoins.
Aujourd’hui, il existe de nouvelles bases de données SQL distribuées, appelés new SQL, comme par exemple Google Spanner ou Yugabytes qui résolvent ces difficultés de montée en charge et de distribution géographique. Ils sont cependant réservés aux projets très importants qui ont besoin d’une réplication et d’un sharding géographique pour une distribution des requêtes par continent / zone géographique.
Les propriétés ACID
Dans le contexte des bases de données, les propriétés ACID sont les propriétés qui garantissent qu'une ou plusieurs opérations d’écriture et ou de lecture formant un ensemble appelée transaction, est exécutée de façon fiable.
L’atomicité garantie qu’une transaction se fait totalement ou pas du tout. Si seule une partie de la transaction peut être effectuée, il faut revenir à l’état initial. Par exemple, en cas de crash complet (coupure de courant etc), il faut pouvoir revenir à un état stable.
La cohérence garantie que toute transaction respectera les contraintes d’intégrité des données.
L’isolation garantie que l’exécution de plusieurs transactions simultanément produirait le même effet que si les transactions étaient effectuées l’une après l’autre.
La durabilité garantie qu’une fois une transaction est confirmée, elle reste enregistrée même en cas de panne (coupure de courant etc).
Il est courant de dire que le NoSQL ne respecte pas les propriétés ACID, mais ce n’est pas parce qu’elles sont moins biens. C’est justement parce qu’elles ne les respectent pas totalement qu’elles peuvent obtenir de telles performances. Avec exactement le même matériel (mêmes serveurs, même réseau), il est beaucoup plus coûteux en performance d’appliquer strictement l’ACID pour toutes les opérations.
Aujourd’hui cela devient totalement faux, car il est fréquent que les bases de données NoSQL permettent des transactions ACID, si vous en avez besoin. C’est le cas depuis MongoDB 4.2.
Les opérations sur un document sont déjà ACID et il est aujourd’hui possible de réaliser des transactions sur plusieurs documents de manière ACID.
Popularité des bases de données
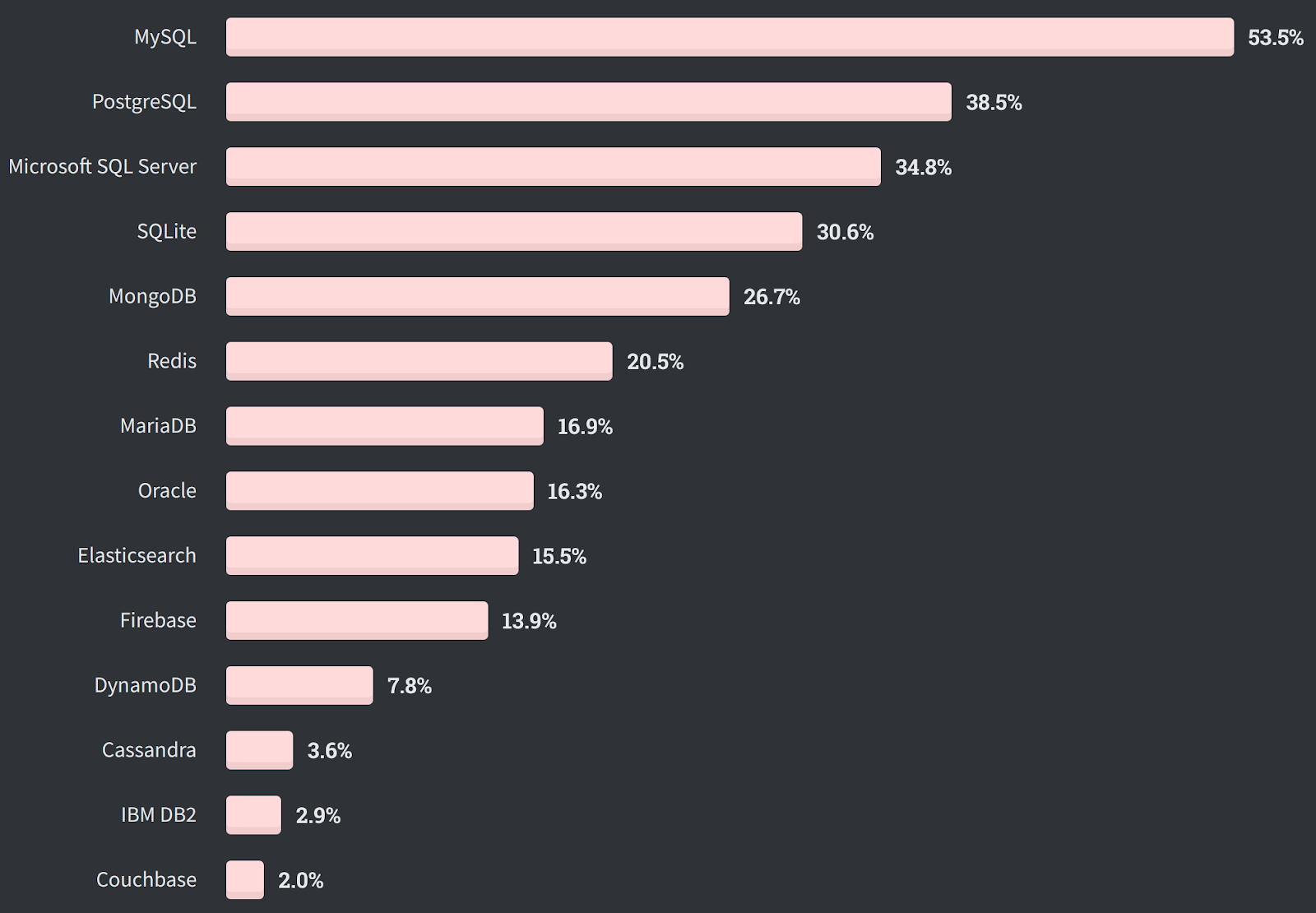
Si les bases de données relationnelles restent les plus utilisées aujourd’hui, le développement du NoSQL a explosé avec MongoDB en tête qui est de loin la plus populaire :

Dans les 15 bases de données les plus utilisées nous retrouvons :
Dans l’ordre d’utilisation, pour le SQL : Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM Db2, SQLite, Microsoft Access, MariaDB, Teradata et Microsoft Azure SQL.
Dans l’ordre d’utilisation, pour le noSQL : MongoDB (orientée document), Redis (orientée clé / valeur), Elasticsearch (orientée recherche), Cassandra (orientée colonnes), Splunk (orientée recherche).
MongoDB la base de données NoSQL la plus populaire
MongoDB s’est imposée largement comme la base de données la plus populaire en NoSQL. Nous allons voir ensemble les raisons de ce succès.
Contrairement au SQL où il faut définir ses modèles en amont et où il est complexe de les changer, MongoDB offre une très grande flexibilité avec ses schémas flexibles. Vous pouvez très facilement ajouter ou retirer des champs au fur et à mesure que les besoins de vos applications changent.
En tant que développeur d’applications Web nous pensons nos relations et nos données en objets car ce sont des objets qui seront utilisés en JavaScript en front ou quel que soit le langage en back. Il est très agréable d’utiliser MongoDB car le stockage se fait avec des documents comme des objets JSON.
La montée en charge horizontale est simple avec MongoDB et des projets l’utilisent sans problème sur 160 instances avec plus d’un pétaoctet de données, comme par exemple Baidu (le Google chinois). Les projets sont nombreux à migrer depuis du SQL.
Le fait de pouvoir imbriquer des documents dans d’autres documents rend les requêtes en lecture et en écriture souvent plus performantes avec MongoDB qu’avec une base SQL. Il n’y a en effet pas plusieurs tables à consulter.
Toutes les limites qui peuvent être avancées pour l’utilisation d’une base de données NoSQL : besoin de transactions ACID (atomicity, consistency, isolation, durability), besoin de requêtes supportant les jointures etc ont toutes été mises levées dans les dernières versions de MongoDB. Il n’y a rien qu’une base de données SQL puissent faire que MongoDB ne puisse faire, mais l’inverse n’est pas du tout vrai.
Parmi les bases de données NoSQL MongoDB est la plus populaire car elle peut tout faire (transactions ACID multi documents, recherches textuelles, requêtes géospatiales etc). Si des besoins particuliers se font sentir, elle est souvent utilisée en parallèle avec une base SQL ou une base de données NoSQL spécialisée (par exemple ElasticSearch ).
LA base de données : l’exemple de Facebook

Il n’y a pas une base de données meilleure que toutes les autres, chaque base de données possède un cas d’usage optimal (un sweatspot ).
Ne prenez pas pour référence les GAFAMs car si aux premiers abords vous pouvez retrouver des technologies connues, par exemple MySQL pour Facebook, il faut bien comprendre qu’il ne s’agit pas de MySQL seul, de nombreuses technologies propriétaires sont utilisés pour gérer la réplication, le sharding et le caching.
Donc même si Facebook utilise bien plusieurs milliers de serveurs MySQL, il s’agit d’un fork complètement personnalisé pour leurs besoins... ils n’utilisent pas le langage SQL et utilisent un moteur de stockage appelé MyRocks (base de données clé/valeur utilisant majoritairement la RAM) utilisant RocksDB.
Ils utilisent un système propriétaire, appelé TAO qui est un système complexe comprenant une API d’accès aux bases de données, un cache et une base de données orientées graphes. Il est conçu pour être hautement distribué géographiquement et optimisé pour la lecture pour tout ce qui est graphe social (relations entre les utilisateurs).
Les applications Facebook font des requêtes à TAO qui va répartir et traduire les requêtes vers le système de cache, des requêtes SQL sur les bons data center etc.
Ce n’est bien sûr qu’un petit aperçu, ils utilisent plusieurs dizaines d’autres systèmes propriétaires pour leur système de base de données (par exemple Wormhole pour l’invalidation du cache ou Binlog Server pour la réplication court terme).
Vous comprenez donc que dire "que comme Facebook utilise MySQL alors son projet Big Data peut l’utiliser aussi" est complètement faux.
Cet exemple a pour objet de vous faire comprendre deux choses sur les bases de données.
Premièrement, c’est un sujet extrêmement complexe qui n’a pas de solution miracle applicable à tous les cas d’usage.
Deuxièmement, vous n’êtes pas Facebook et n’avez pas 300 ingénieurs et chercheurs à plein temps simplement pour architecturer et gérer vos bases de données.
Ne choisissez donc jamais une technologie de base de données pour faire “comme Google, Facebook ou Amazon”. Vous n’avez pas les mêmes besoins et les mêmes problématiques et ne pourrez accéder de toute manière qu’à une infime partie de leur architecture (la plupart étant propriétaire).
Nous allons maintenant voir ensemble comment choisir votre base de données.
Choisir sa base de données
Avant de choisir une base de données il faut vous poser quelques questions.
Les limites du théorème de Brewer (CAP)
Premièrement, dois-je privilégier la cohérence (toutes les requêtes en lecture donnent le même résultat) et la tolérance au partitionnement (la base de données reste disponible malgré des problèmes réseaux affectant certaines instances et qu’elles ne peuvent plus communiquer entre elles) ou la disponibilité (la base de données reste disponible même si une partie des nodes sont en panne, c’est la garantie que toute requête reçoive une réponse) et la tolérance au partitionnement. En effet, selon le théorème de Brewer, une base de données distribuées peut garantir deux des trois contraintes mais jamais les trois.
Dans les bases de données relationnelles (RDBMS comme MySQL ), ce sera la disponibilité et la cohérence (CA) qui seront respectées. La cohérence car toutes les écritures et lectures se font sur le même serveur et donc il ne peut y avoir d’inconsistance. Pour la disponibilité, comme la base de données n’est pas distribuée elle est toujours disponible.
Dans des bases de données CP (cohérence + tolérance au partitionnement). La cohérence est maintenue en ayant une instance responsable de l’écriture et de la lecture, les autres instances répliquent les données pour assurer la durabilité des données. C’est le cas de MongoDB par exemple :
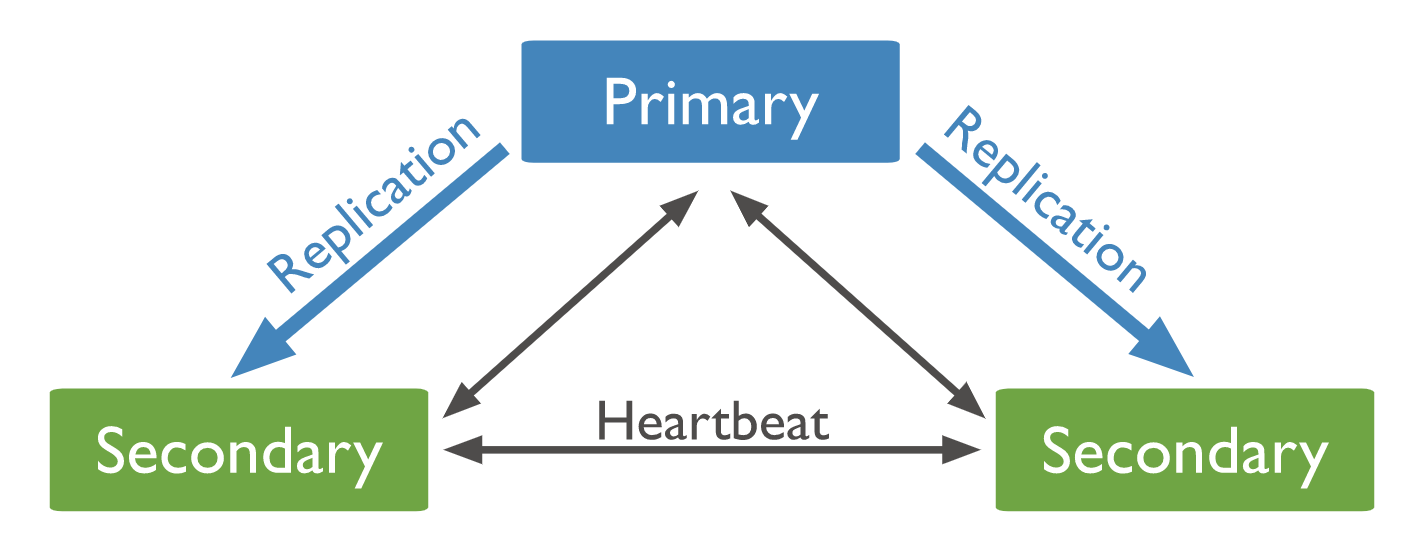
Si l’instance leader, appelée Primary est en panne, les autres instances vont élire un nouveau leader et la base de données sera indisponible pendant ce processus (de quelques secondes). La garantie que toute requête aura une réponse n’est pas assurée.
A noter qu’il est tout à fait possible de manuellement configurer MongoDB en mode AP, c’est-à-dire en privilégiant la disponibilité sur la cohérence. Dans ce cas, toutes les instances Secondary peuvent répondre aux requêtes en lecture (conférant une disponibilité en lecture mais non en écriture). La cohérence n’est pas garantie car il existe un délai de réplication et il n’est donc pas garantie que les données d’une Secondary soient les mêmes que sur celles qui ont été écrites sur la Primary. C’est ce qu’on appelle l’eventual consistency. A savoir que les données sur la Primary seront toujours celles qui prévaudront et seront répliquées, au bout d’un certain temps sur les Secondary. Vous pouvez également configurer le niveau de cohérence en indiquant qu’une opération d’écriture n’est validée que si la majorité ou toutes les instances l’ont prise en compte. Dans ce cas, vous aurez la cohérence, une disponibilité en lecture mais pas en écriture et une tolérance au partitionnement. En revanche, les opérations d’écriture seront beaucoup plus lentes car il faudra avoir le retour de n Secondary (et non plus juste de la Primary) en plus avant de valider l’opération.
Dans les bases de données AP, l’architecture ne repose pas sur un leader. Cela permet d’assurer la disponibilité et la tolérance aux partitions mais pas la cohérence. Les opérations de lecture et d’écriture peuvent être menées sur n’importe quelle instance et les opérations d’écritures sont ensuite répliquées sur les autres instances donnant une eventual consistency. C’est le cas par exemple de Cassandra.
De même Cassandra peut être configuré pour avoir plus de cohérence (consistency level ) en réduisant la disponibilité.
Quelle est l’ordre de grandeur de la taille de mes données ?
Deuxièmement, quel est le volume de données que je vais devoir gérer : quelques Gigaoctets, quelques téraoctets, plusieurs centaines de téraoctets ou des pétaoctets ?
Par exemple, la principale base de données de Facebook fait quelques dizaines de pétaoctets (quelques dizaines de milliers de téraoctets).
Si vous dépassez quelques dizaines de téraoctets vous pouvez oublier le SQL classique et devez vous diriger vers du NoSQL.
Ai-je besoin d’une distribution géographique importante ?
Par exemple, j’ai des clients dans plusieurs zones et souhaite une latence optimale. Je dois donc distribuer horizontalement ma base de données en zones.
Il faut alors que la base de données supporte la partition automatique des données.
Par exemple, c’est possible avec le sharding par zone dans MongoDB :

Ce n’est pas possible en SQL classique du tout. Il faut utiliser d’autres systèmes par-dessus qui vont gérer la partition et la réplication. C’est beaucoup plus complexe à mettre en œuvre.
Optimisation des écritures ou des lectures
Ma base de données va-t-elle subir une grande majorité de lecture, d’écriture ou plus ou moins équilibré ? Par exemple pour Facebook, le ratio est de 99% de lecture et 1% d’écritures.
Il faut que la technologie supporte l’optimisation des écritures ou des lectures. Cela peut être par plusieurs stratégies.
MongoDB peut optimiser les deux avec le sharding en distribuant les requêtes d’écritures et de lecture entre plusieurs groupes d’instances répliquées.
Compétences de l’équipe
Ai-je les compétences dans mon équipe pour administrer une base de données moi-même ?
Il faut maîtriser principalement la sécurité (authentification, autorisation, TLS ), les sauvegardes (automatisation, contrôle et roll-back), la réplication (mise en place de plusieurs instances pour dupliquer les données afin d’assurer la durabilité), la répartition des données et des opérations de lecture / écriture (partition des données), la configuration entre plus de cohérence ou plus de disponibilité.
Si vous ne pouvez pas devenir expert dans une technologie pour gérer toutes ces problématiques il faut que des DBaaS soient disponibles pour le faire pour vous.
C’est notamment le cas de MongoDB avec Atlas.
Ai-je les compétences dans mon équipe pour établir une architecture complexe mixte (plusieurs systèmes de base de données) pour optimiser chacun de mes besoins ?
Si ce n’est pas le cas il vaut mieux se tourner sur une base de données general purpose comme MongoDB que très spécifique, comme neo4j.
Stade du projet
Est-ce un projet démarrant sans vision claire des modèles de données et des relations, des requêtes limitantes (bottlenecks) et des besoins en écritures / lectures, ou au contraire un projet mature déjà très architecturé ?
Il sera beaucoup plus aisé de démarrer avec MongoDB qu’avec du SQL sans une vision claire. Restructurer une base SQL après son déploiement est en effet beaucoup plus complexe et long.
La base de données MongoDB
Le nom de la base de données vient de humongous qui signifie gigantesque.
Le projet a démarré en 2007 et est écrit en C++.
C’est la base de données NoSQL la plus utilisée. L’entreprise MongoDB a levé plus de 300 millions de dollars. Elle a aujourd’hui une capitalisation de plus de 23 milliards ce qui en fait la technologie de base de données la plus prometteuse.
Elle est utilisée par plusieurs dizaines de milliers d’entreprises comme le New York Times, Ebay, Disney, MTV, Adobe, Baidu etc.
Nous allons voir brièvement les principaux avantages de MongoDB qui font son immense succès puis nous étudierons quelques cas intéressants d’utilisation.
Vous pouvez sans plus attendre commencer notre formation MongoDB.
Une très grande flexibilité permise par les documents
Le fait que des documents d’une même collection puissent avoir des champs différents et qu’il est très simple d’ajouter / supprimer des champs à toute une collection permettent aux développeurs de progresser sur leurs projets beaucoup plus rapidement.
Ils n’ont pas besoin de passer énormément de temps sur la modélisation des données, car il est facile de la faire évoluer au fil des besoins.
Il est extrêmement simple d’optimiser les requêtes si besoin en créant des index (qui vous sont même suggérés sur Atlas !) ou en modifiant les relations et l’imbrication entre les documents.
Une montée en charge progressive simplifiée
Pour débuter il est simple de créer une architecture répliquée (replica set) de trois instances assurant une excellente durabilité des données.
Lorsque le besoin se fera sentir il est simple d’ajouter plus d’instances et d’accepter la lecture sur les instances secondaires pour accélérer certaines requêtes.
Il est aussi simple de partitionner ses données suivant la clé de partition souhaitée et la stratégie de partition voulue (par hash ou par intervalle), et enfin de partitionner ses données par zone géographique.
Des performances suffisantes pour le Big Data
Aucun problème pour gérer des pétaoctets de données avec MongoDB, comme Baidu ou Ebay, de nombreux projets utilisent MongoDB pour gérer des données massives avec des besoins importants en lectures et écritures.
Une grande flexibilité de configuration
Le nombre de configuration possibles est incroyable.
Que ce soit pour optimiser la disponibilité ou la cohérence (write and read concerns, configuration des shards), la gestion d’erreurs (retryable reads / writes), effectuer des transactions ACID (transactions multi-documents)... il existe une solution MongoDB !
Des offres cloud ou DBaas
Suivant que vous soyez plus ou moins à l’aise avec l’administration de bases de données, vous pouvez architecturer votre base de données MongoDB complètement vous-même (sur des VPS ) ou complètement par MongoDB Atlas en choisissant le ou les clouds et datacenters que vous voulez chez AWS, Google Cloud ou Azure.
Vous pouvez aussi trouver d’autres offres DBaas comme celle d’ AWS pour MongoDB.
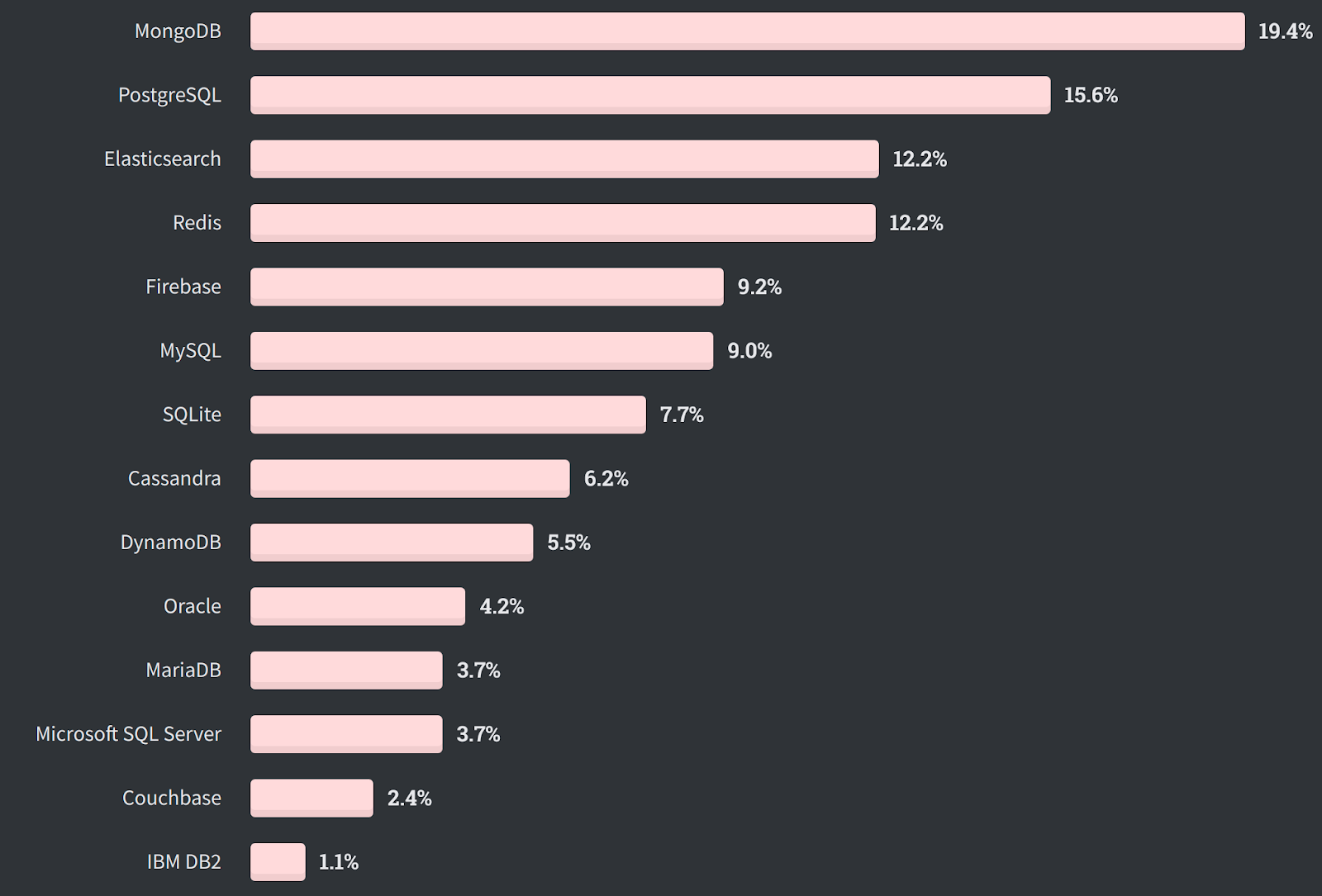
Une communauté énorme
Aucun problème pour trouver de l’aide et la réponse à vos questions. Le fait qu’il s’agisse de loin de la base de données NoSQL la plus utilisée :
C’est aussi la base de données que les développeurs professionnels souhaitent le plus apprendre, et ce pour la cinquième année consécutive :
Un excellent support
Les équipes de MongoDB sont disponibles pour vous aider à concevoir ou résoudre des problématiques avancées.
Bien sûr ces services sont payants, mais savoir qu’en cas de difficulté plusieurs centaines d’expert MongoDB sont disponibles est quand même rassurant.
Un écosystème incroyable
Le fait que l’entreprise MongoDB ait énormément de ressources humaines et financières lui a permis de développer un nombre d’outils performants considérables.
La base de données peut être utilisée avec des drivers officiels dans tous les langages majeurs : JavaScript, C, C#, C++, PH, Python, Ruby, Scala, Haskell, Perl, Dart, Go, Java, Erlang et Rust.
Commençons par Atlas qui est son offre DBaas permettant de déployer des clusters répliqués et shardés en quelques clics. Tout en assurant une sécurité par défaut : utilisation de TLS, Iaccess-list, gestion fine des permissions etc.
Elle offre des outils pour visualiser et manipuler facilement les données dans un navigateur avec Atlas Data Explorer ou dans une application avec MongoDB Compass.
Elle propose également deux shells : mongo et son plus récent mongosh offrant l’autocomplétion et la colorisation, ainsi qu’une extension VS Code.
Elle offre un service permettant de s’intégrer parfaitement à Kubernetes pour gérer facilement ses clusters.
Même chose pour Kafka, un connecteur est aussi proposé pour persister les données ou utiliser les données des topics Kafka.
Elle offre un connecteur pour tous les outils BI.
Elle offre un outil de visualisation très simple et ergonomique : MongoDB Charts.
Enfin, elle propose une offre serverless appelée MongoDB Realm.
Quelques exemples d’utilisation
MongoDB chez Craiglist
Le principal site de petites annonces au monde, Craiglist (l’équivalent américain de Leboncoin) utilisait MySQL pour stocker les 1,5 millions nouvelles petites annonces quotidiennes. C’était la seule technologie disponible lorsqu’ils ont commencé.
La complexité de l’architecture pour faire scaler MySQL rendait le coût troélevé et la flexibilité était très mauvaise. Les performances ont commencé à être détériorées et les processus de sauvegarde et d’archivage des données étaient très longs et complexes. Pour pallier tous ces problèmes, ils ont commencé alors à chercher une nouvelle technologie.
Ils se sont alors tournés vers MongoDB avec succès et stockent aujourd’hui plus de 2 milliards d’annonces.
La raison principale était la possibilité de stocker chaque annonce avec toutes ses métadonnées dans un seul document, ce qui permet d’avoir d’excellentes performances en lecture et écriture.
L’autre raison majeure est la possibilité de modifier les champs très facilement conférant une grande flexibilité pour les développeurs. Ils n’ont plus besoin de mettre en oeuvre des migrations longues et complexes.
La dernière raison est la possibilité d’auto-sharding (partition automatique des données) offerte par MongoDB qui a permis de diminuer drastiquement la complexité du scaling.
MongoDB chez Ebay
Ebay doit gérer 1 milliard d’annonces en ligne chaque jour et plus de 170 millions d’acheteurs actifs. Pour ce faire, elle gère plus de 3000 instances de bases de données NoSQL gérant plusieurs pétaoctets de données.
Pour chaque projet, les administrateurs des bases de données (DBA) évaluent la technologie à utiliser selon six critères : la disponibilité, la cohérence, la durabilité, la récupérabilité, la montée en charge et la performance.
Voici leur architecture, leur priorité étant de n’avoir aucun downtime :

Ils utilisent un sharding côté application, c’est-à-dire que la partition des données est gérée par un système propriétaire d’Ebay.
Pour chaque zone, par exemple ici les Etats-Unis, un replica set de 7 instances MongoDB est réparti entre trois data centers.
Seule la Primary accepte les écritures. En revanche, pour une meilleure disponibilité, les lectures sont autorisées sur les Secondary.
Les instances du replica set sont réparties de telle sorte que même si un data center est en panne (réseau, courant etc), la disponibilité sera garantie, les deux autres data centers pouvant prendre le relais dans cette configuration.
Pour diminuer le temps d’élection en cas de panne, la priorisation est faite sur les instances les plus proches de la Primary. Ainsi, si la Primary dans DC1 tombe en panne, ce seront les deux Secondary dans DC1 qui seront prioritaires.
Les instances de DC2 ne peuvent devenir Primary que dans le cas où DC1 est en panne. Dans ce cas, c’est l’instance qui a validé la dernière opération d’écriture qui est prioritaire.
Cette architecture est ensuite montée en charge avec du sharding :
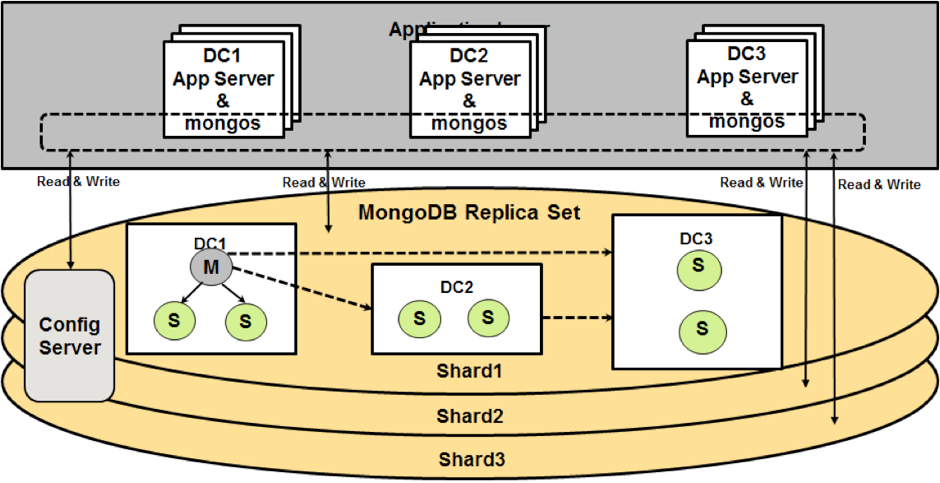
Le catalogue de produits d’Ebay utilise cette architecture avec 50 instances MongoDB assurant un volume d’écritures et de lectures énorme sans compromettre la disponibilité qui reste la priorité.
A noter que cette architecture a été mise en place avant que MongoDB permettent un auto-sharding par zone géographique (version 3.4). Ebay utilise aujourd’hui cette faculté pour ses projets.
Chicago vers une smart city
La ville de Chicago a choisi MongoDB pour analyser ses données en temps réel. Les données sont énormes et très différentes car elles proviennent des 15 départements principaux : police, pompiers, transports, travaux publics, propreté, feux de signalisation, service pour les plaintes liées au bruit, stationnement, bâtiments abandonnés etc. Plus de 7 millions de rangées sont enregistrées chaque jour.
Le chef des données de la ville utilise avec son équipe un outil de géolocalisation en temps réel basé sur MongoDB. Il permet de mieux gérer la circulation, les incidents et la propreté.
En effectuant également de l’analyse de données, la ville peut identifier des problèmes récurrents comme par exemple un problème de feu ou des nouveaux problèmes de circulation.
Un des nombreux exemples d’analyse est le fait qu’après 7 jours consécutifs de plainte pour le ramassage des ordures dans une zone, une plainte pour dératisation était effectuée. Cela permet à la ville de mieux prioriser la gestion des déchets et d’éviter l’apparition de rats.
MongoDB offre tous les outils pour mener à bien ce projet : requêtes géospatiales, textuelles et auto-sharding.
La terminologie de MongoDB
Nous allons voir les termes principaux de MongoDB pour que vous sachiez vous repérer dans l’écosystème.
Terminologie relative au stockage
BSON : signifie binary JSON. C’est le format utilisé par MongoDB pour stocker les documents. C’est une représentation binaire du format JSON qui comporte plus de types. Nous y reviendrons en détail.
Document : c’est l’unité de base du stockage dans MongoDB. Vous pouvez le voir comme un objet JSON, mais il est stocké en BSON qui est un format binaire illisible par les humains. Les documents peuvent être imbriqués dans d’autres documents, comme des objets dans des objets. Un document comporte des paires de clés / valeurs. Dans le contexte de MongoDB les clés sont appelés champs (fields) :
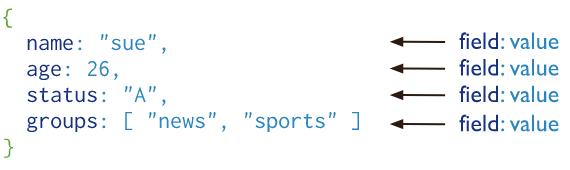
Collections : MongoDB stocke les groupes de documents similaires ou ayant le même objectif dans des collections. On peut voir une collection comme une table dans les bases de données relationnelles. Une collection fait partie d’une unique base de données. Les documents dans une même collection peuvent avoir des champs différents, même si ce n’est pas le plus fréquent.

Databases : une base de données comporte plusieurs collections. Chaque base de données a ses propres fichiers sur le système de fichiers. Une instance MongoDB peut avoir de nombreuses bases de données, ce qui est souvent le cas.
Terminologie relative à l’architecture
Cluster : il faut faire attention car cela signifie deux choses dans l’univers MongoDB. Sur Atlas, le DBaaS de MongoDB, il s’agit simplement d’un ensemble gratuit ou payant d’instances. Sur MongoDB hors Atlas, cela signifie sharded cluster, voir plus bas pour le sharding.
Replica set : ensemble d’instances MongoDB, appelées nodes, constitué au minimum de trois nodes, et qui permet d’assurer la durabilité des données en copiant toutes les données sur trois nodes au minimum. Il permet d’augmenter la disponibilité car si la node recevant les écritures (et par défaut les lectures), appelée Primary, tombe en panne, une des deux autres nodes, appelées Secondary, la remplacera (c’est ce qu’on appelle un automated failover, ou protocole Raft).
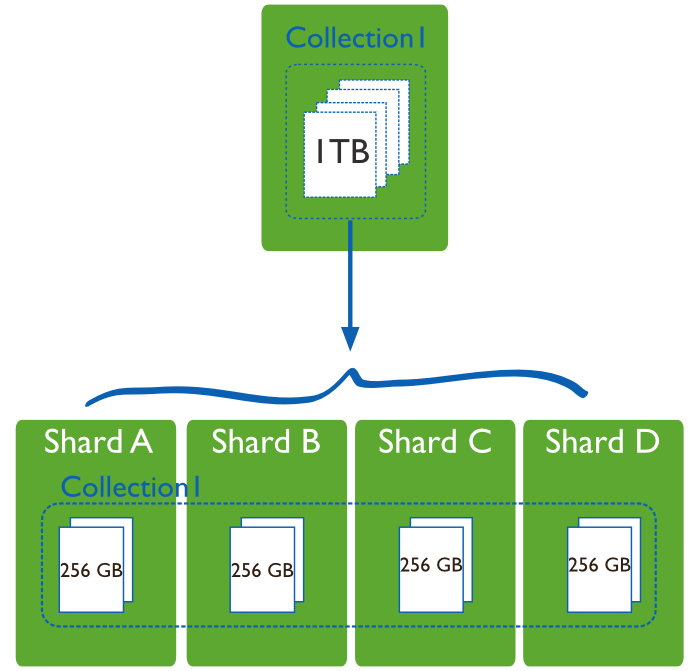
Sharding : mécanisme de montée en charge horizontal permettant de partitionner les données entre plusieurs replica set (chaque shard étant répliqué au moins 3 fois) :
Terminologie relative aux programmes
mongod : il s’agit du daemon MongoDB, c’est-à-dire du processus en arrière plan non interactif permettant de faire tourner le serveur MongoDB. Il gère les requêtes pour écrire / lire des données et les accès aux données. Il effectue les tâches de gestion en arrière-plan. Il faut passer par un shell ou un driver pour communiquer avec lui.
mongo et mongosh : il s’agit des shell MongoDB, à savoir d’une interface interactive utilisable dans un terminal pour envoyer des instructions à mongod et recevoir des informations. Le shell utilise le langage JavaScript.
Driver : librairie cliente pour interagir avec MongoDB en utilisant un langage particulier, par exemple du Dart ou du JavaScript.
L’architecture de MongoDB
Pour résumé l’architecture de MongoDB :.

MongoDB Query Language (MQL) est la couche qui va traduire les messages des drivers ( Node.js, PH etc) ou du shell ( mongo ou mongosh ) qui sont dans un format appelé BSON wire protocol (du BSON prévu pour être échangé sur le réseau), en opérations MongoDB (lecture, écriture, etc).
MongoDB Document Data Model permet de gérer les index, les namespaces et les structures de données. A savoir, quelles opérations bas niveau doivent être réalisées pour aboutir aux opérations MongoDB demandées. Il gère aussi la réplication si elle est activée.
Storage Layer est la couche gérant le stockage des données (appels systèmes, écritures sur les disques, structure des fichiers et compression).
Securiy est la couche qui s’occupe de l’authentification, des autorisations, de la gestion des utilisateurs, de la gestion TLS et du chiffrement des données.
Admin est la couche permettant de gérer les bases de données (création, suppression etc), des collections etc.
Maintenant que vous connaissez la terminologie, vous êtes prêt à commencer notre formation MongoDB.
L'écosystème MongoDB
MongoDB Compass
MongoDB Compass est une application permettant de visualiser facilement ses données. Elle permet également de manipuler ses données en faisant des opérations CRUD sur un document. Enfin, elle permet de déboguer et d’optimiser ses requêtes en analysant la performance des requêtes et l’utilisation des index.
Il est développé en JavaScript avec Electron.
Il permet de se connecter en local pendant le développement ou sur ses clusters et de retrouver l’ensemble de ses bases de données.
Par exemple :

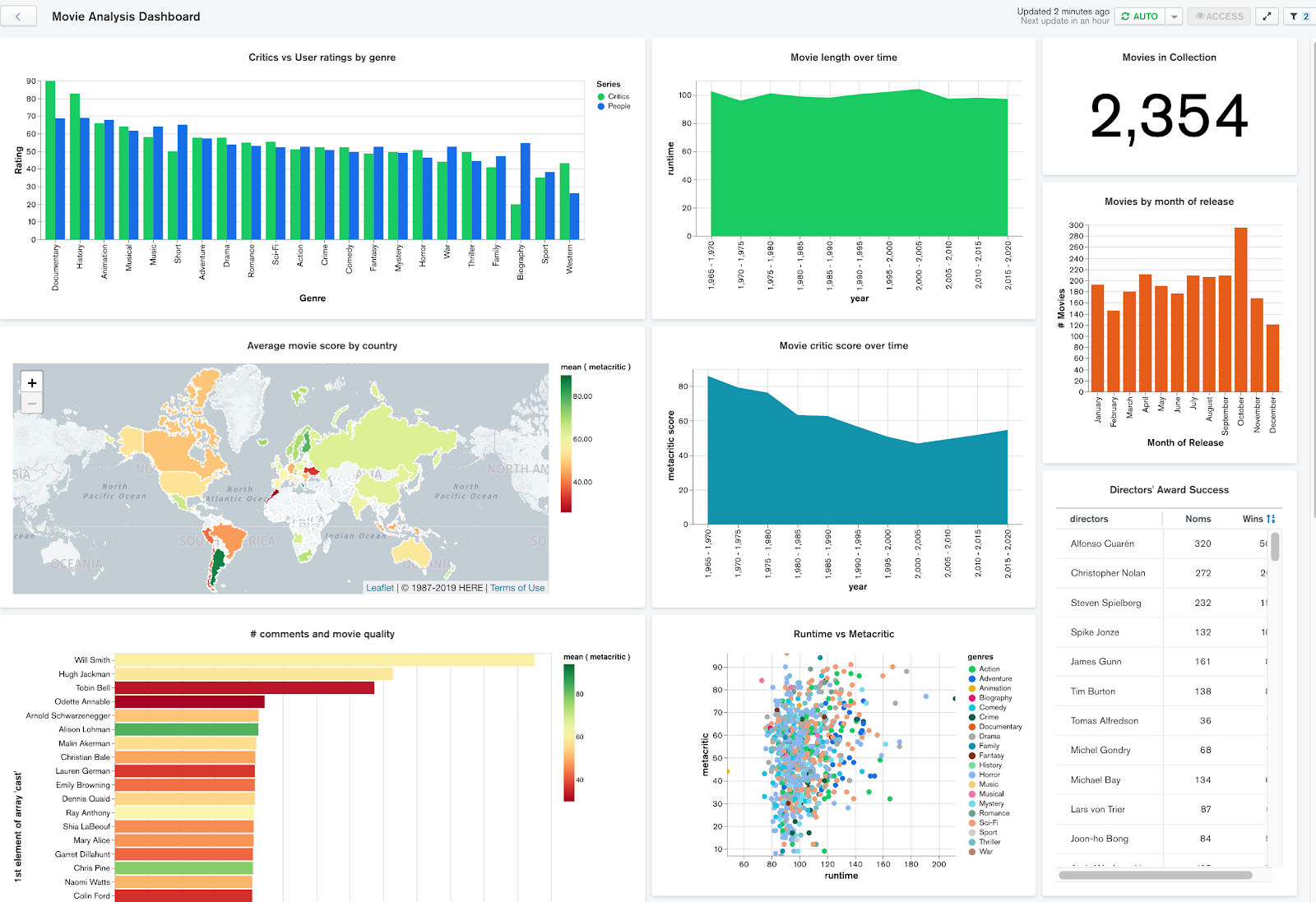
Ici, nous pouvons voir que l’utilisateur est connecté au cluster My Cluster en localhost sur le port 27017.
Nous pouvons voir qu’il a 15 base de données ( databases ) comportant 34 collections.
Voici un exemple de mise à jour de données dans Compass :

Une des fonctionnalités très appréciables est la faculté de faire des agrégations directement dans l’application et de les exporter dans le langage de son choix. Excellent pour générer ses agrégations facilement !
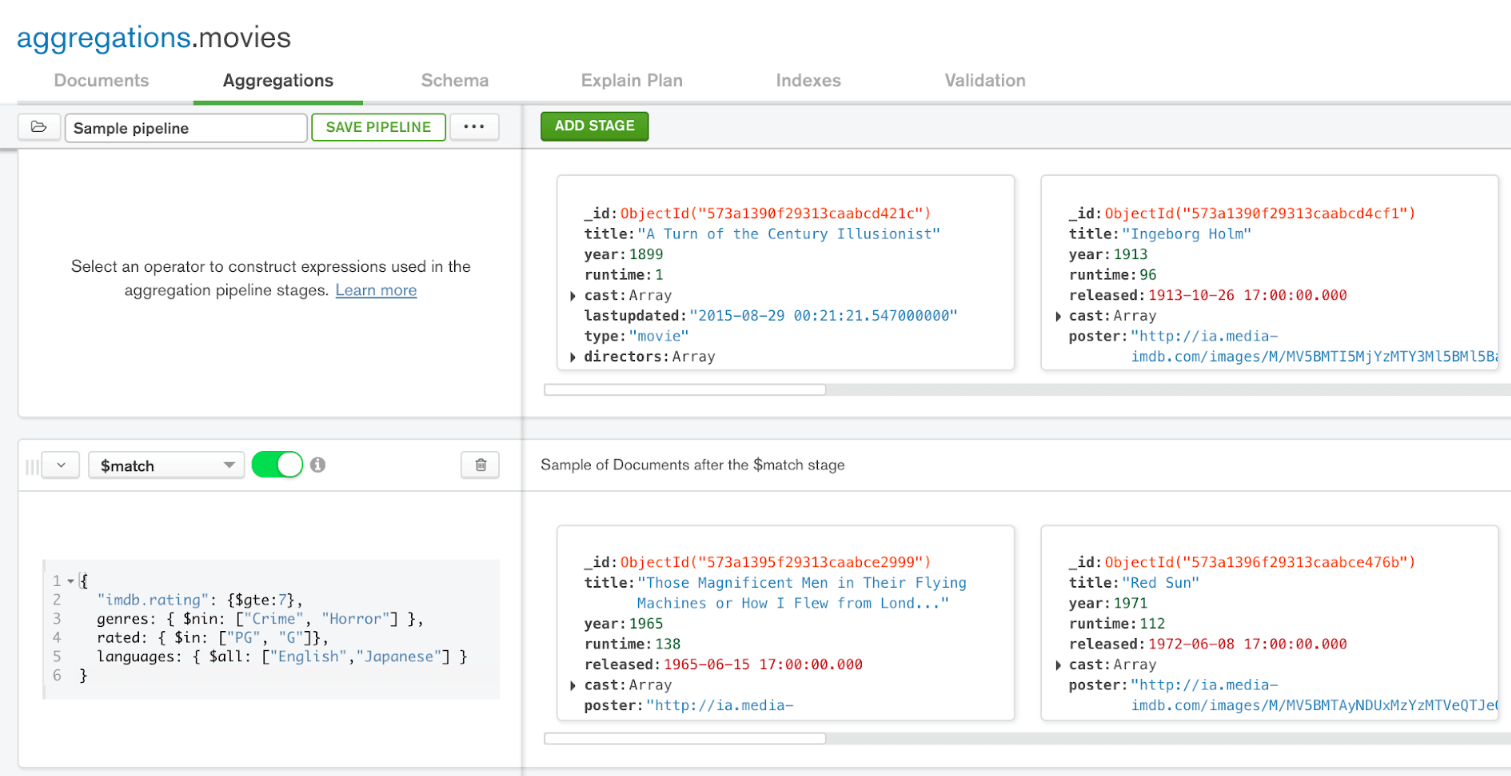
Nous apprendrons à nous en servir en détail dans la formation. Cet outil est indépendant d’ Atlas, donc même si vous n’utilisez pas le DBaaS de MongoDB vous pouvez vous en servir !
L’extension VS Code
L’extension officielle MongoDB pour Visual Studio Code permet de travailler plus efficacement, sans avoir à installer et configurer de driver.
Nous allons la montrer en détail car elle permet de facilement explorer ses données et de prototyper ses requêtes, parfait pour découvrir MongoDB !

MongoDB Atlas
En plus bien sûr de fournir l’hébergement et l’administration des bases de données sur les principaux hébergeurs du cloud :
Atlas propose de nombreux services dont nous allons voir les principaux. Ces services sont inclus si vous hébergez vos bases de données chez MongoDB.
MongoDB Charts est un outil Atlas permettant de créer des graphiques pour visualiser ses données rapidement, ou même d'effectuer des agrégations puis de visualiser les résultats avec des graphes :
Mongo Data explorer est l’équivalent de Compass mais directement dans le navigateur et uniquement pour Atlas :
Il permet quelques fonctionnalités supplémentaires par rapport à Compass comme la suggestion de schémas ou d’index si des anomalies dans les requêtes sont détectées, la création d’index avancés pour la recherche (permettant une configuration fine des scores de recherche textuelle pour les besoins de votre application), la visualisation des requêtes lentes et des collections les plus consultées en temps réel.
MongoDB realm est la solution cloud de MongoDB pour le serverless et le mobile.
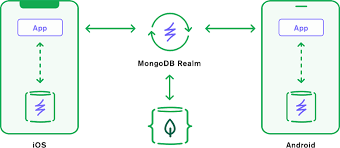
Il permet notamment le stockage de données local sur les mobiles, avec la possibilité également de synchroniser automatiquement les données, ou de les resynchroniser lorsque le réseau est de nouveau disponible, avec un cluster Atlas.
Ce ne sont que les fonctionnalités majeures d’ Atlas, mais il y en a plein d’autres.
Maintenant que vous connaissez l'essentiel sur les bases de données et MongoDB, il ne vous reste plus qu'à démarrer notre formation MongoDB !



